The Next Bottleneck in AI Agents Isn't the Model, It's the Training Loop
The gap between frontier models on most agent tasks has narrowed. Two teams can use the same model and get very different results in production. The difference is increasingly the training loop.
A year ago, the primary question in most agent evaluations was: which model?
That question still matters, but it matters less than it did. The gap between frontier models on most agent tasks has narrowed. Two teams can use the same model and get very different results in production. The difference is increasingly what they do after the model is chosen.
That means the training loop.
What a Training Loop Actually Is
The term gets used loosely. Here is what it actually consists of:
-
Task generation — creating a distribution of tasks representative of what the agent will face in production. Too narrow, and the agent overfits. Too broad, and it learns nothing specific.
-
Environment interaction — the agent takes actions inside a simulated or real environment and receives observations. The quality of the environment determines the quality of this step.
-
Feedback collection — capturing what happened: actions, observations, outcomes, failures.
-
Scoring — evaluating agent behavior against a reward function. This is where most teams underinvest.
-
Iteration — updating the agent based on what you learned and running again.
The loop is only as strong as its weakest component. A great model with a weak training loop will plateau early.
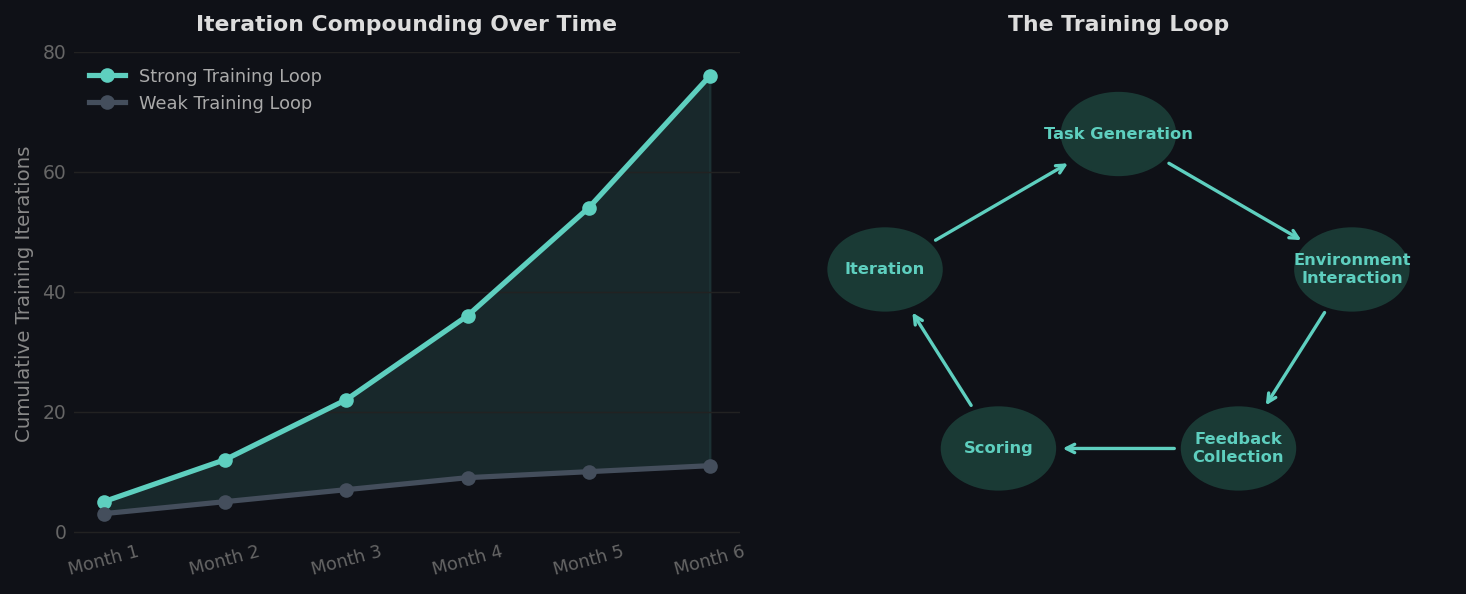 How training iterations compound over time with strong vs weak loops, and the five components of a training loop.
How training iterations compound over time with strong vs weak loops, and the five components of a training loop.
Why Models Are Becoming Interchangeable
Foundation model capabilities are converging on several benchmark tasks. This is not a criticism of model labs. It reflects normal technology maturation. Differentiation at the model layer is hard to sustain because training improvements spread across the field relatively quickly.
What doesn't spread quickly is institutional knowledge about how to train agents for specific domains. A team that has run 500 training iterations on customer service agent behavior has accumulated signal that is genuinely hard to replicate. That signal lives in their reward design, their environment, their curriculum structure.
It does not live in their model choice.
Weak Loops vs. Strong Loops
A weak training loop has recognizable characteristics. Tasks are not representative of production. Reward functions are binary: success or failure, with little signal in between. Environment fidelity is low, so lessons learned do not transfer to production. Iteration cycles are slow because the environment is brittle or logging infrastructure is incomplete.
A strong loop looks different. Tasks are sampled from a distribution that reflects real production variance. Rewards are multi-signal: task completion, efficiency, error recovery, and avoiding unnecessary actions each carry weight. Environments are high-fidelity enough that training performance predicts production performance.
The difference in agent performance between these two loops, given identical models, is large.
Compounding Advantage
Training loops compound. A team with a strong loop runs more iterations. More iterations mean more signal. More signal means better reward calibration. Better calibration means faster learning on the next round.
After six months, two teams that started with the same model can have agents with meaningfully different capabilities, purely because one team's loop was faster and higher-fidelity.
You can copy someone's model. You cannot quickly copy six months of accumulated training signal and reward design.
Where to Invest
Given that the loop determines long-term performance, the question is where to focus engineering effort.
Reward design comes first. A precise, multi-signal reward function is the foundation everything else builds on. Sparse or poorly calibrated rewards waste every subsequent training iteration.
Environment fidelity comes second. If the environment does not reflect how real software behaves, training signal does not transfer. This is also the most common underinvestment.
Task distribution comes third. Most teams train on the happy path. Production agents fail on edge cases. The task distribution should be weighted toward the cases that actually break the agent.
Infrastructure comes last in priority because it is a solved problem. Parallelism, logging, replay: these are table stakes. Spending engineering time here instead of on the first three is the most common sequencing mistake.
theta builds RL training environments for production AI agents. We handle environment fidelity so your team can focus on reward design and iteration speed.