What Gaming and Robotics Already Know About Training in Simulated Environments
Simulation-based training is not a new idea. Gaming and robotics researchers spent a decade working through the hard problems — and the lessons transfer directly to enterprise agent training.
Simulation-based training is not a new idea.
Gaming and robotics researchers spent a decade working through the hard problems: how do you train in a simulated environment and get behavior that transfers to the real world? When does simulation help, and when does it mislead? How do you build a simulator fidelity enough to be useful without being so complex that it is impractical?
Enterprise agent teams are now facing versions of the same questions. The prior work is directly relevant.
What Gaming and Robotics Demonstrated
The notable examples are familiar. OpenAI's Dota 2 agent, trained entirely in simulation, eventually defeated professional human teams. DeepMind's work on Atari and later on StarCraft showed that agents trained in simulated environments could reach and exceed human-level performance on complex tasks.
Robotics went a different direction. Labs training physical robots could not afford to use real hardware for the majority of training iterations. Robots break, reset times are slow, physical experiments are expensive. Simulation became a practical requirement, not a theoretical preference.
In both cases, the conclusion was similar: simulation is the only path to the scale and repeatability that serious training requires.
Why Simulation Is Required
Three properties make simulation necessary for serious agent training.
-
Safety — An agent in training will take incorrect actions. In production, incorrect actions have consequences: they affect real customers, corrupt real data, trigger real workflows. Simulation provides a space where the agent can fail without cost.
-
Scale — Training on production would mean one agent, one task at a time. Simulation allows hundreds of instances running in parallel, each accumulating experience. The volume of training signal available in simulation has no practical equivalent in production.
-
Repeatability — Debugging agent failures requires being able to reproduce them. Production environments are not repeatable. Simulation can be reset to a known state, making it possible to isolate why a specific failure occurred and verify that a fix works.
These three properties together explain why every serious training effort in gaming and robotics moved to simulation. They apply equally to enterprise agents.
The Sim-to-Real Problem
Simulation introduces a risk: the agent learns behavior that works in the simulator but does not transfer to the real environment. This is called the sim-to-real gap, and it is the central challenge in simulation-based training.
In robotics, the gap showed up as agents that performed well in simulation but failed to handle the physical variability of the real world. Surfaces were slightly different. Lighting changed. Motor responses were imprecise.
For enterprise agents, the equivalent problem is environment fidelity. If the simulated Zendesk or Salesforce interface does not accurately reflect how the real software behaves, an agent trained there will struggle in production.
Environment fidelity is not a secondary concern. It is the mechanism by which training performance predicts production performance.
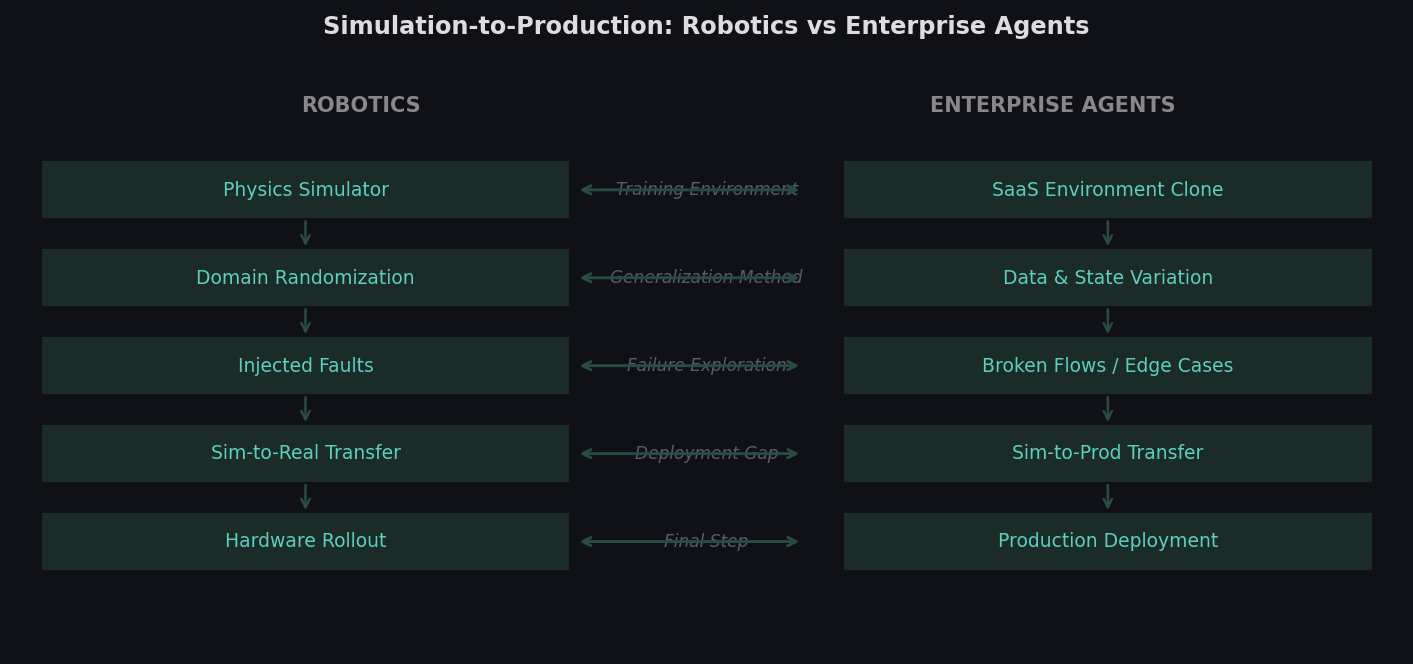 How the simulation-to-production pipeline in robotics maps structurally to enterprise agent training. The problems are different in domain but identical in structure.
How the simulation-to-production pipeline in robotics maps structurally to enterprise agent training. The problems are different in domain but identical in structure.
Domain Randomization
One of the more useful insights from robotics training is domain randomization.
Rather than trying to build a perfect simulator, robotics researchers introduced random variation into simulation parameters: lighting, surface friction, object positions, motor noise. Agents trained across this range of variation became more robust because they could not rely on any single environmental property being consistent.
The lesson transfers. Enterprise agents that train only on clean, well-structured data and straightforward task flows become brittle. They overfit to the training distribution.
Introducing variation in simulation produces agents that handle production variance better. The goal is not to make simulation harder for its own sake, but to ensure the training distribution is wide enough that the agent develops general problem-solving behavior rather than narrow pattern matching.
Systematic Failure Exploration
Robotics labs also developed a practice of deliberately engineering failure cases into simulation. Rather than hoping the training distribution would naturally include hard cases, they designed for them.
This matters because rare failures in production often represent the most important cases to handle. A customer service agent that fails on standard refund requests is obviously broken. An agent that fails on edge cases causes quieter, harder-to-catch problems.
In simulation, you can construct these cases deliberately, control their frequency in the training distribution, and verify that training on them produces the desired behavior. This is distinct from just running the agent on more tasks.
How This Maps to Enterprise Agents
The structural similarity between robotics training and enterprise agent training is close enough that the lessons transfer with relatively little adaptation.
The target environment is SaaS software rather than a physical system, but the core challenge is the same: build a high-fidelity simulator, introduce appropriate variation, design for failure cases, and ensure training performance predicts production performance.
What differs is that SaaS environments are more deterministic than physical environments. Their variability is in data states, user inputs, API responses, and workflow branches. Domain randomization for enterprise agents means sampling from the real distribution of those variables.
The teams in gaming and robotics that succeeded at simulation-based training generally shared one property: they treated environment quality as a first-order concern, not an afterthought. The agents that failed to transfer from simulation to reality usually did so because the simulator was not good enough, not because the training algorithm was wrong.
That is a useful prior for enterprise agent teams to carry.
theta applies the environment engineering principles that simulation-based training has validated over the past decade. We build RL environments for production AI agents.