Why Your AI Agent Fails on Edge Cases — And Why More Prompting Won't Fix It
Most agent teams discover the same thing within a few weeks of shipping to production. The agent handles common cases well, then edge cases appear. The instinct is to fix the prompt. That works until it doesn't.
Most agent teams discover the same thing within a few weeks of shipping to production.
The agent handles the common cases well. Response quality is good. Demos look clean. Then a ticket comes in with a slightly unusual structure, a workflow hits an unexpected state, or a user does something the prompt never anticipated. The agent stalls, loops, or produces output that is technically coherent but wrong in context.
The instinct is to fix the prompt. Add more instructions. Cover the case explicitly. And for a while, that works. Then the next edge case appears.
This is not a prompt engineering problem. It is a training problem.
What Edge Cases Actually Are
An edge case is not just a rare input. It is any scenario that falls outside the distribution the agent was implicitly trained or prompted to handle.
In production enterprise software, that distribution is large. Tickets arrive with missing fields, conflicting information, or references to data that no longer exists. Workflows branch in ways that were not anticipated during design. Users deviate from expected flows. API responses come back in states that are technically valid but practically unusual.
For a customer service agent, a standard refund request is well-covered. A refund request on an order that was partially fulfilled, partially cancelled, and linked to a corporate account with custom billing rules is an edge case. It is also not that rare.
The long tail of these cases is what breaks production agents. And the long tail is, by definition, underrepresented in any static training set or set of prompt instructions.
Why Prompting Has a Ceiling
Prompt engineering is effective for shaping model behavior within a known distribution. If you know the cases you want to handle and can describe them clearly, prompts work well.
The problem is that edge cases are precisely the cases you did not anticipate. You cannot write instructions for scenarios you have not seen. And even when you do encounter them and add instructions, you are patching one instance without necessarily addressing the class of problem it belongs to.
There is also a compounding cost. As prompts grow longer to cover more cases, the model's ability to prioritize instructions degrades. A prompt covering 40 edge cases is harder for the model to reason from than a prompt covering 5. The fix for one failure can introduce fragility elsewhere.
Prompting is a distribution problem solved by specification. Edge cases are a distribution problem solved by training.
What Static Training Datasets Miss
Many agent systems are built on top of base models fine-tuned on curated datasets. The datasets are clean, well-structured, and representative of expected behavior. That is also their limitation.
Real production data is not clean. It reflects the actual variance of user behavior, software state, and workflow complexity. A dataset of resolved support tickets covers the tickets that were resolved the usual way. It does not cover the tickets that required judgment calls, escalations, or unconventional sequences of actions.
The agent trained on curated data learns the pattern of the training set. When production deviates from that pattern, the agent has no mechanism for recovery. It has not seen failure and learned to navigate it. It has only seen success and learned to replicate it.
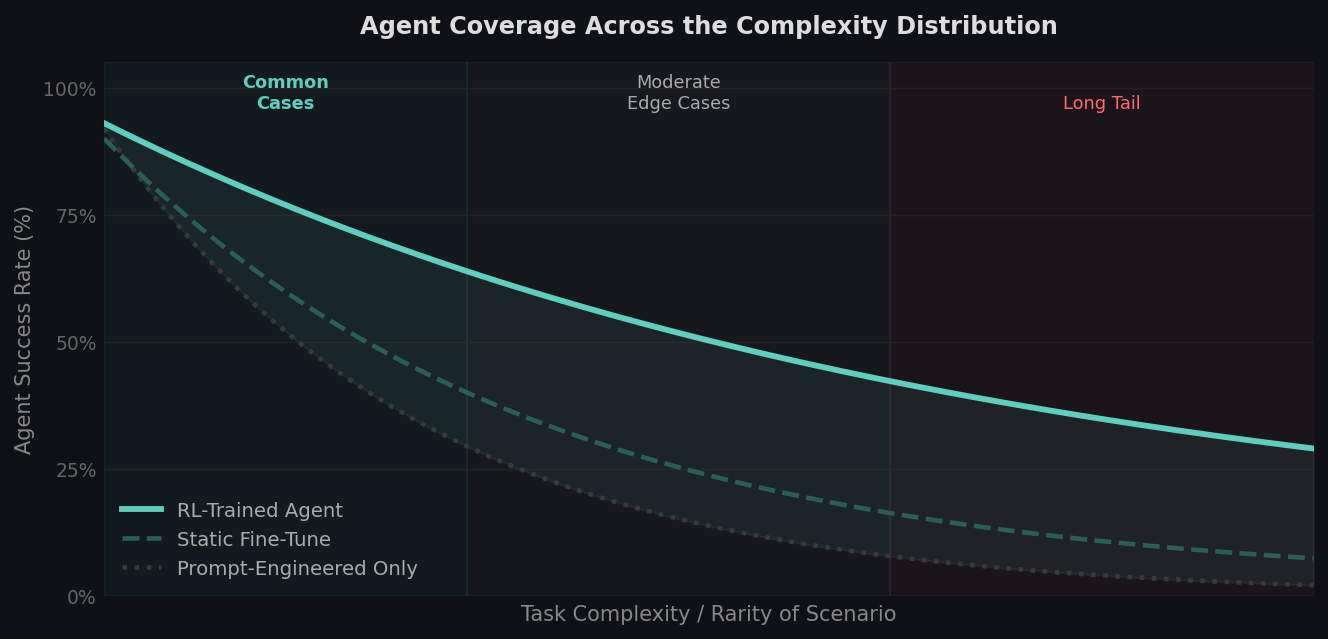 How agent coverage changes across task complexity. Prompt-engineered and statically trained agents handle common cases well but degrade sharply as scenario complexity increases. RL-trained agents maintain higher coverage across the distribution.
How agent coverage changes across task complexity. Prompt-engineered and statically trained agents handle common cases well but degrade sharply as scenario complexity increases. RL-trained agents maintain higher coverage across the distribution.
What Reinforcement Learning Adds
Reinforcement learning addresses the edge case problem through a different mechanism. Instead of specifying correct behavior upfront, you define what good outcomes look like and let the agent learn to achieve them through trial and error across a wide range of scenarios.
The key difference is failure exposure. An RL-trained agent has encountered thousands of variations of a task, including the failure modes. It has learned what recovery looks like, which actions lead to dead ends, and how to navigate ambiguous states. That knowledge is embedded in the policy, not in the prompt.
This matters most precisely in the cases that prompting cannot reach. When the agent hits a scenario it has never seen, an RL-trained agent has a richer set of learned behaviors to draw from. It has generalized from training variation rather than memorized training examples.
The Infrastructure That Makes RL Possible
RL training requires an environment. The agent needs somewhere to take actions, receive observations, and get feedback on outcomes. For enterprise agents, that means a functional replica of the software they operate in: the CRM, the ticketing system, the workflow tools.
Building that environment is the primary reason most teams do not pursue RL training even when they understand its value. Cloning enterprise software into a controlled, instrumented environment with meaningful reward signals is a significant engineering undertaking.
But that cost is a one-time infrastructure investment, not an ongoing maintenance burden. Once the environment exists, the training loop can run continuously. Every edge case the agent encounters in production becomes a candidate for the training distribution. The agent improves incrementally rather than requiring manual prompt updates for each new failure.
The teams that invest in this infrastructure early tend to pull ahead on reliability. Not because their models are better, but because their agents have seen more of the distribution they operate in.
A More Durable Fix
When an agent fails on an edge case, the immediate question is: what is the fastest path to fixing this specific failure? The answer is usually a prompt update. That is fine for individual cases.
The more useful question is: what is the system that prevents this class of failure from recurring? That question points toward the training loop, not the prompt.
Prompt engineering and RL training are not mutually exclusive. Prompts handle the known distribution. Training handles the unknown one. The teams that treat them as complementary rather than alternatives tend to build agents that are both capable on common cases and resilient on edge cases.
The prompt defines what the agent should do. Training determines what it can do when things go wrong.
theta builds RL training environments for production AI agents. We clone real enterprise software into containerized environments with instrumented reward signals, including edge case injection and adversarial conditions.