The Gap Between Demo and Production for AI Agents
The demo worked. Everyone saw it. Three months later, the same team is fielding complaints about reliability and patching edge cases weekly. Nothing changed — the demo was just a different environment.
The demo worked. Everyone saw it. The agent handled the task, produced the right output, and the room was convinced. Three months later, the same team is fielding complaints about reliability, patching edge cases weekly, and wondering what changed.
Nothing changed. The demo was just a different environment.
The gap between a controlled demo and a live production deployment is not a polish problem. It is a structural one. And most agent teams discover it only after they have shipped.
What the Demo Actually Tests
A demo is, by design, a best-case scenario. The inputs are chosen in advance or are at least familiar. The data is clean. The workflow follows the expected path. The evaluator is present and the cost of failure is zero.
These conditions produce good results because the agent was implicitly built for them. The prompts were written against these cases. The fine-tuning data reflects these scenarios. The evaluation during development measured performance on these inputs.
None of that is wrong. It is just incomplete. A demo tests what the agent can do when everything is set up for it to succeed. Production tests what the agent does when nothing is set up at all.
 Six dimensions where demo conditions diverge from production reality. Each gap is a source of agent failures that are not visible during development.
Six dimensions where demo conditions diverge from production reality. Each gap is a source of agent failures that are not visible during development.
What Actually Breaks in Production
The failures are not random. They cluster around a predictable set of conditions.
-
Data state variance — Production data is not curated. Tickets have missing fields. Customer records have conflicting information. Order states are partially updated. The agent was trained on clean data and encounters messy reality.
-
Unexpected workflow branches — Real users do not follow the intended flow. They submit information out of order, interrupt multi-step processes, or arrive at a state that the workflow was not designed to handle. The agent encounters a branch it has never been trained on.
-
System-level failures — APIs time out. Third-party services return unexpected status codes. Authentication tokens expire mid-session. In a demo, none of this happens. In production, it happens regularly, and the agent has no learned behavior for it.
-
Session state accumulation — In a demo, each run starts clean. In production, the agent may be operating in a session with prior context, partially completed tasks, or state left by a previous interaction. The agent has to reason about a starting state it was never trained to handle.
-
Latency and feedback loops — Production systems have variable response times. Actions that produce immediate feedback in a demo may take seconds or timeout entirely. Agents that were not trained with this variance in mind behave differently when it appears.
None of these are exotic edge cases. They are normal properties of real enterprise software.
Why the Gap Widens Over Time
The first week in production is often fine. The agent handles the common cases. The volume of unusual inputs is low. Issues are caught manually and addressed with prompt updates.
The problem compounds. Each week introduces new edge cases. Each prompt update covers one scenario but may interact unpredictably with others. The complexity of the prompt grows while the underlying agent capability stays fixed.
Meanwhile, the software environment continues to change. UI updates, API version changes, workflow modifications: any of these can shift the conditions the agent was trained on. Without an active training loop, the agent does not adapt. It degrades.
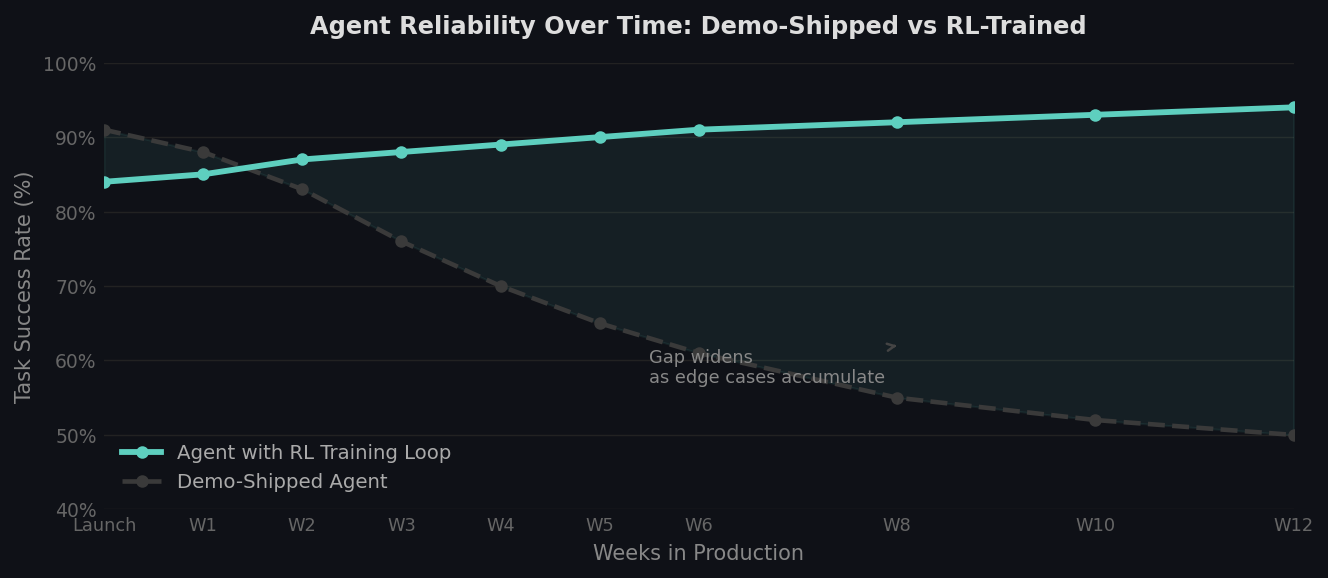 Agent reliability over 12 weeks in production. Demo-shipped agents tend to degrade as edge cases accumulate. Agents with active RL training loops maintain and improve reliability over the same period.
Agent reliability over 12 weeks in production. Demo-shipped agents tend to degrade as edge cases accumulate. Agents with active RL training loops maintain and improve reliability over the same period.
The Underlying Mismatch
The root cause is a mismatch between training conditions and deployment conditions. The agent was built in a controlled environment and deployed into an uncontrolled one. The behaviors it learned are calibrated for conditions that production does not provide.
This mismatch is not fixed by making the agent smarter in general. It is fixed by closing the gap between training and deployment. The agent needs to have encountered production-like conditions during training: variable data, broken workflows, system failures, ambiguous states.
That requires a training environment that mirrors production reality with enough fidelity to produce transferable behavior. Not a perfect replica, but one that captures the variance the agent will face.
The agent does not fail in production because it is not capable enough. It fails because it was not trained on what production looks like.
Closing the Gap
The teams that close this gap most effectively do it before shipping, not after. They build or use training environments that introduce production-like conditions intentionally: messy data, interrupted workflows, injected failures, variable response states.
The agent trained in this environment does not just learn the happy path. It learns what failure looks like, how to detect it, and what actions lead toward recovery. Those behaviors transfer to production because they were developed under production-like conditions.
The alternative is learning in production itself, which means real users encountering real failures while the agent iterates. That is slower, more expensive, and visible to customers.
The demo-to-production gap is real and predictable. The question is not whether an agent will encounter it. It is whether the team has prepared the agent to handle it before it ships.
theta builds RL training environments that mirror production conditions before your agent ships. Messy data, broken flows, system failures, adversarial states — all instrumented with reward signals so your agent learns to handle them.